E004: Computing \(\sigma(n)\) at Scale — Sieve vs. Factorization¶
Tags: number-theory, quantitative-exploration, numerics, optimization
See: Valid Tags.
Highlights¶
Benchmark bulk sieve vs. per-number factorization.
Find runtime crossover points as \(N\) grows.
Validate correctness on sampled inputs.
Goal¶
Benchmark two practical ways to compute the sum-of-divisors function:
Sieve method: compute all \(\sigma(1..N)\) in one pass.
Factorization method: compute \(\sigma(n)\) per-number from the prime factorization.
Research question¶
For a range of bounds \(N\):
which approach is faster?
where is the crossover point?
what are the memory tradeoffs?
Why this qualifies as a mathematical experiment¶
Both methods are mathematically equivalent, but performance depends on constants, caching, and implementation details. This is a quantitative exploration of algorithmic behavior grounded in number-theory structure.
Experiment design¶
Method A: divisor-sum sieve (bulk computation)¶
Compute sigma[1..N] by adding each divisor to its multiples (as in E003).
Method B: per-number factorization¶
Factor each \(n\) (e.g. using a precomputed prime list up to \(\sqrt{N}\)) and compute:
If
Measurements¶
wall-clock runtime vs. \(N\) (multiple trials, median)
peak memory (rough estimate acceptable for v1)
correctness cross-check: random sample where both methods agree
Outputs¶
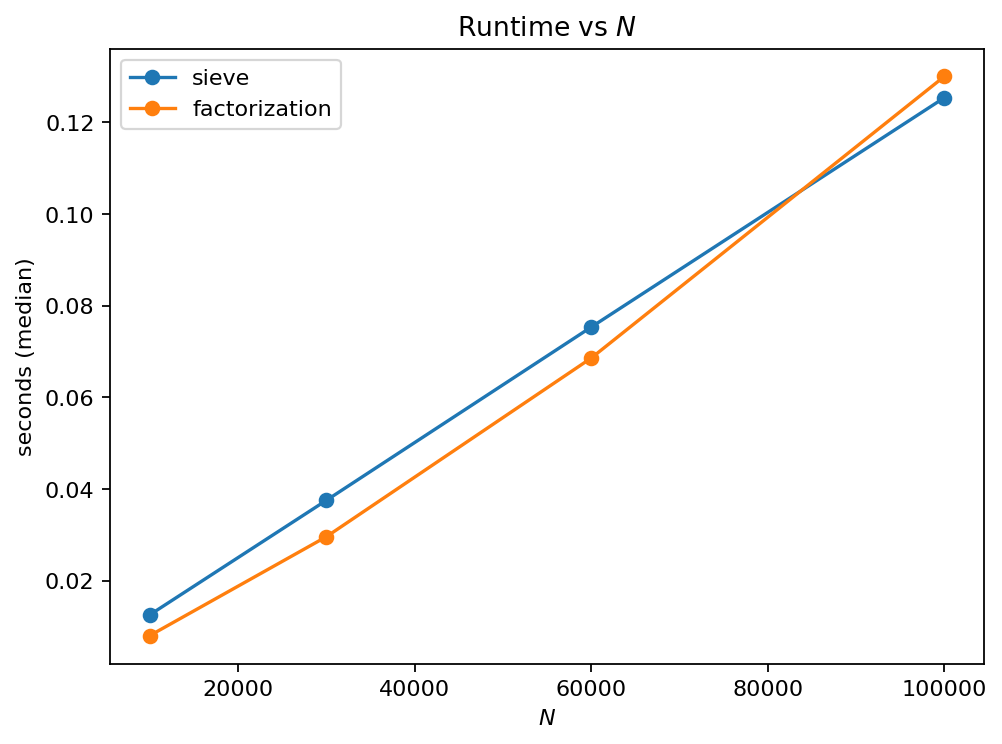
plot: runtime vs. \(N\) for both methods
short table: \(N\), runtime(A), runtime(B), speedup
How to run¶
make run EXP=e004
or:
uv run python -m mathxlab.experiments.e004
Notes / pitfalls¶
Factorization becomes expensive quickly; keep the factorization method limited to moderate \(N\).
Use integer arithmetic for correctness checks (
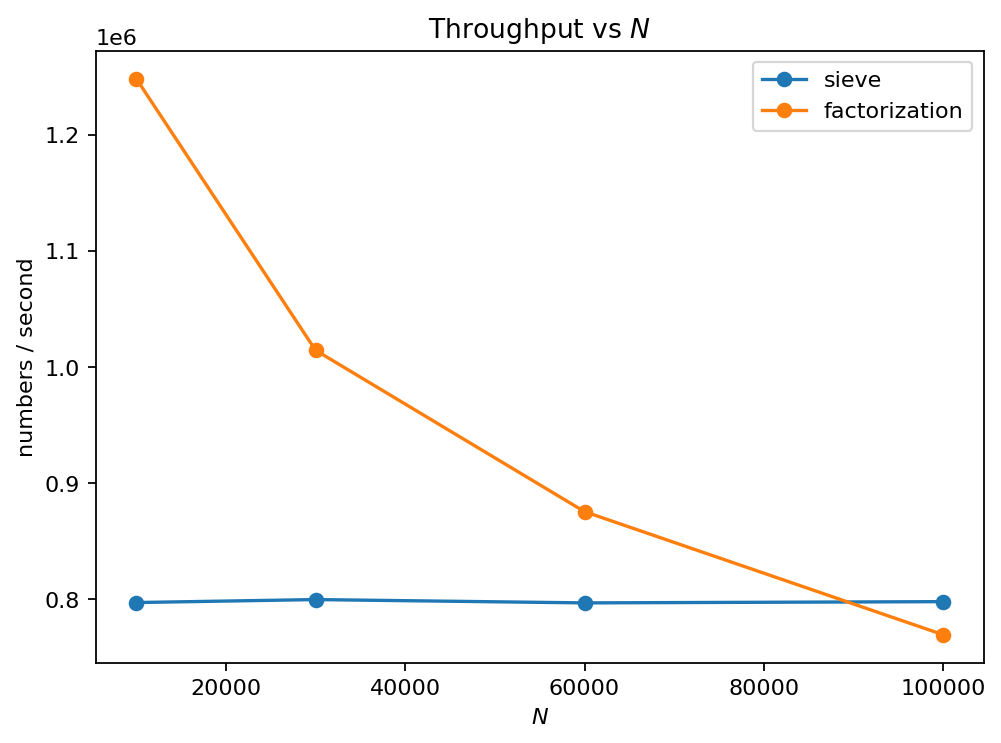
sigma[n] == 2*netc.).Report both runtime and effective throughput (numbers processed per second).
Extensions¶
Add a third method using smallest-prime-factor (SPF) sieve for fast factorization.
Compare pure Python vs.
numpyarrays for Method A.Turn the benchmark into a reusable utility for later experiments.
Published run snapshot¶
If this experiment is included in the docs gallery, include the published snapshot (report + params).
Reproduce:
make run EXP=e004
Parameters¶
n_values:
10000, 30000, 60000, 100000trials:
3
Results (median runtime)¶
N |
sieve [s] |
factorization [s] |
speedup (sieve/fact) |
|---|---|---|---|
10000 |
0.0103 |
0.0056 |
1.83 |
30000 |
0.0303 |
0.0205 |
1.48 |
60000 |
0.0605 |
0.0476 |
1.27 |
100000 |
0.1020 |
0.0877 |
1.16 |
Notes¶
Sieve computes all σ(1..N) at once; factorization recomputes structure per number.
Factorization is capped to moderate N to keep runtime reasonable in pure Python.
params.json (snapshot)
{
"max_n_factor": 100000,
"n_values": [
10000,
30000,
60000,
100000
],
"trials": 3
}
References¶
See References.